(상황)
서버 배포 시 아래와 같은 오류가 확인되었습니다.
AbortError: Redis 연결이 끊어지고 명령이 중단되었습니다. 처리되었을 수 있습니다.
RedisClient.flush_and_error에서(/var/app/current/node_modules/redis/index.js:362:23)
그리고 ElastiCache의 최근 연결 지표에서
유통 당시 읽기 복제본 연결연결이 끊어졌는지 확인한 후 다시 연결했습니다.

(원인)
1. Elastic BeansTalk 구성 – 추가 배치를 사용한 지속적 배포로 인해 ElastiCache 로드 증가

API 서버는 평균 23개의 인스턴스를 실행하며,
서버가 구축되면 추가 구축으로 롤링 비율이 75%로 설정됩니다.
이 설정으로 인해 서버 프로비저닝 시 동시에 17개의 인스턴스가 생성됩니다.
다음 지표로
배포 시 ElastiCache의 현재 연결 수가 크게 증가하여 이그레스 네트워크 대역폭을 초과함을 알 수 있습니다.
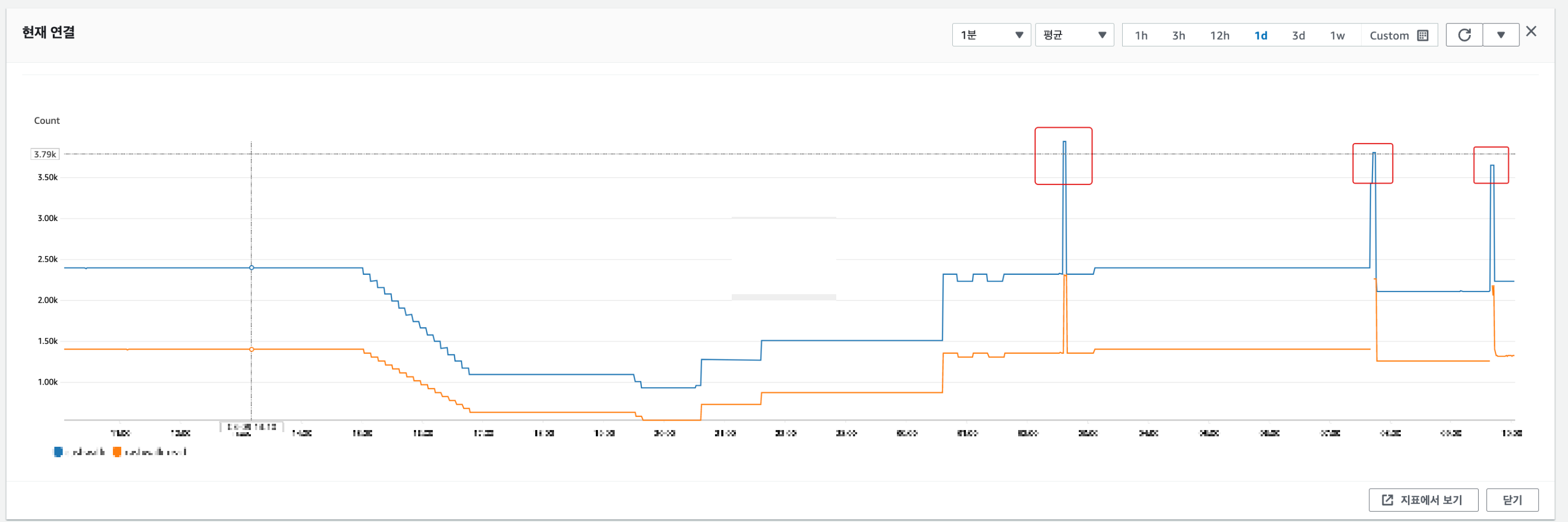

여기서 주의할 점은
요점은 총 3번의 배포 중 현재 1차 배포는 연결이 끊긴 상태이고 2차, 3차 배포만 실패했다는 점입니다.
다른 지표를 찾아 차이가 있는지 확인하십시오.
두 번째 출시 이후 메모리 팁 교체확인된 것.
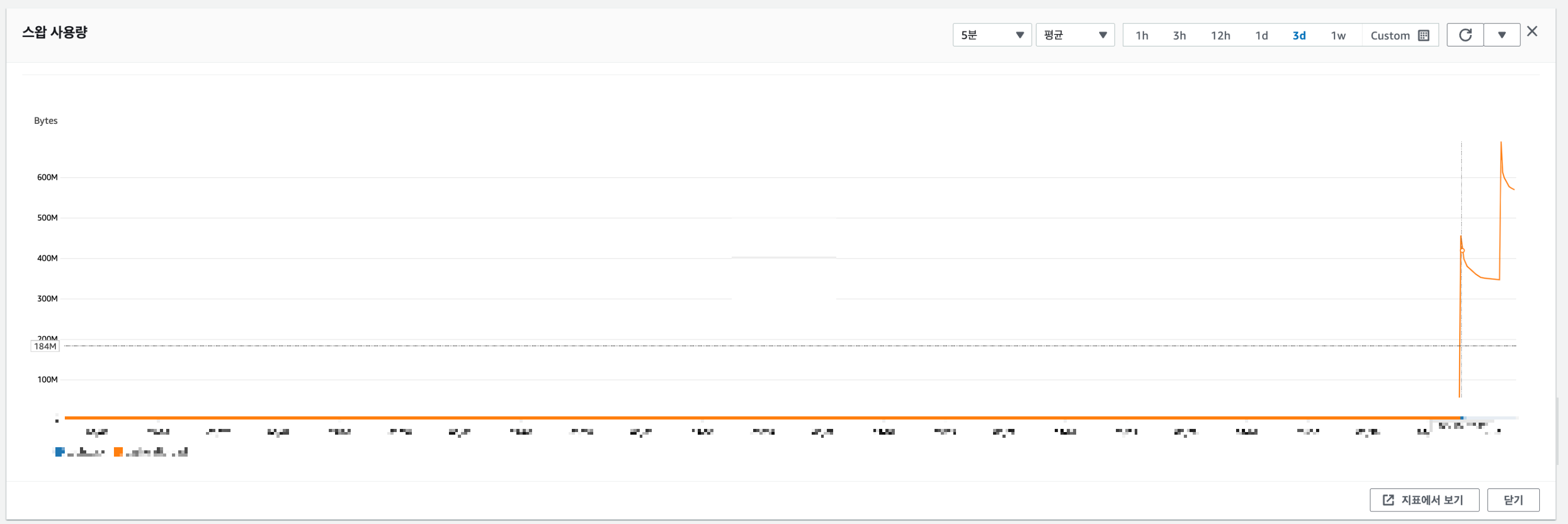
2. 스왑 공간 사용 원인
스왑 공간이 사용되는 경우 ElastiCache가 기본 메모리가 부족할 때 발생합니다.
공식 AWS 설명서따라서,
네트워크 대역폭 병목 현상이 발생하면 버퍼 사용량이 계속 누적되어 메모리가 고갈되고 성능에 영향을 미칠 수 있습니다.

1번과 연결해서 생각해보면
배포 당시 새 인스턴스의 급증으로 인해 ElastiCache에 대한 많은 수의 요청이 발생했습니다.
아웃바운드 네트워크 트래픽에 대한 초과 대역폭때문에 네트워크 대역폭 병목 현상했다
버퍼 사용량은 계속해서 누적되고 어느 시점에 메모리 고갈로 인해 사용된 스왑 공간처럼 보인다
3. 결론
스왑 공간을 사용할 때 ElastiCache 성능이 저하되었습니다.
결과적으로 일시적으로 제대로 작동하지 않는 것 같습니다.
다만 성능 저하로 연결 자체가 끊어지는 부분은 아직까지 정확히 파악되지 않았다.
나는 이것을 명확하게 파악한 후에 이것에 대해 더 쓸 계획입니다.
(반응)
1. 서버 프로비저닝 시 롤 비율 변경
비율을 75%에서 30%로 줄임으로써 배포 시 많은 인스턴스가 동시에 생성되는 것을 방지했습니다.
2. 네트워크 전송 대역폭을 초과하는 데이터 구조 및 로직 개선
특대형 데이터가 특정 해시키에 저장되어 있음을 확인,
배포 시 hgetall 명령을 사용하여 이 데이터를 즉시 가져오는 논리가 있음이 확인되었습니다.
키에 저장된 데이터를 공유한 후 충분한 검증을 거쳐 상용 서버에 미러링할 예정입니다.